6篇报告读懂AI大模型
上周六,中国AI布道人,也是中国针对大模型最有发言权的人之一——陆奇,在上海举行小规模演讲。内容涵盖了他对大模型时代的宏观思考,包括拐点的内在动因、技术演进、创业公司结构性机会点以及给创业者的建议。
AI 大模型被认为是新时代的工业革命,新的革命性技术意味着新创新,而创新则意味着新机会。我们一方面要开放心态学习新知;一方面,要理解它可能带来的变化。
报告酱阅读了相关报告并精选其中6篇,帮助我们更全面深度地了解大模型及其机会。本文将从以下三部分分享:
-
AI大模型究竟是什么?
-
技术发展的关键在哪里?有哪些挑战?
-
对普通人来说机遇在哪?

什么是AI大模型
AI大模型是“人工智能预训练大模型”的简称,包含了“预训练”和“大模型”两层含义,二者结合产生了一种新的人工智能模式,即模型在大规模数据集上完成了预训练后无需微调,或仅需要少量数据的微调,就能直接支撑各类应用。
其中,预训练大模型,就像是知道了所有大量基础知识的大学生,甚至博士生,完成了“通识”教育。但他们还是需要实践,需要反馈后的精细调整,才能更好地完成任务。

另外,AI大模型具备通用、可规模化复制等诸多优势,是实现 AGI(通用人工智能)的重要方向。
当前AI大模型包含自然语言处理(NLP)、计算机视觉(CV)等,统一整合的多模态大模型等。例如,ChatGPT就是自然语言处理领域突破性的创新,懂“人话”,说“人话”。超越了以往的自然语言处理模型,可以应对各种自然语言处理任务,包括机器翻译、问答、文本生成等。
简单来看,我们可以将大模型看作一个非常大的知识库,里面存储了大量的信息和知识,可以帮助计算机更好地理解和处理输入的数据。大模型中的每个神经元和参数,共同构成了一个强大的网络,可以对输入的数据,进行高效的处理和转换。
目前,国内已有百度、阿里巴巴、腾讯、华为等公司对 AI 大模型进行开发,各模型系列各有侧重,有些已推出并实现部分应用落地。

-
百度在AI方面布局多年,具有一定大模型先发优势。当前,申请文心一言 API调用服务测试的企业已突破6.5万。在行业大模型上,已经与国网、浦发、吉利、TCL、人民网、上海辞书出版社等均有案例应用。
-
阿里通义大模型在逻辑运算、编码能力、语音处理方面见长,集团拥有丰富的生态和产品线,在出行场景、办公场景、购物场景和生活场景均有广泛应用。
-
腾讯混元大模型已经在广告投放、游戏制作投入使用,目前集团在研究对话式智能助手,预计投入使用后将对QQ和微信生态有一定优化。
-
华为与 B 端合作紧密,预计未来应用以 ToB 为主。此外,华为在算法、算力上储备较为丰厚。比如:“鹏城云脑 II”获全球 IO500 排行五连冠,拥有强大的 AI 算力和数据吞吐能力;华为云 ModelArts 平台的高效处理海量数据能力,7 天完成了 40TB 文本数据处理;盘古大模型最早已经在 2021 年 4 月正式发布,当前盘古大模型训练文本数据高达 40 TB(GPT-3 为 45 TB)。

核心技术及挑战
看过“文心一言”发布会的小伙伴肯定能感受到,尽管“文心一言”展现了足够的文案创作能力,但事先录好的视频,也让人感到信心不足,并且,在使用上,“文心一言”的上下文理解、语义逻辑、多轮对话方面尚有欠缺。
国产大模型真的比不上国际巨头吗?核心差距在哪里?
答案先行:略逊一筹,但仍有追平可能。
大模型通常由数亿到数十亿个参数组成,需要在海量数据上进行训练和优化,才能达到更高的预测准确性和泛化能力。业内人也常说:大模型是“大数据+大算力+强算法”结合的产物。行业发展的关键也在于这三点。
大数据
数据是算法训练的养料,前期需要给模型喂养大量数据,形成模型理解能力,中后期投喂的数据质量决定了模型的精度。
以GPT模型为例,ChatGPT表现更好的原因之一,就是在无监督学习的基础上提供了高质量的真实数据。
但机器学习的数据,需要人工提前标注好,标注就是把初级数据进行加工处理, 转换为机器可识别信息,只有经过大量的训练,覆盖尽可能多的各种场景,才能得到一个良好的模型。
当前,训练的数据来源多为公开数据,比如根据 AlanD. Thompson博士 (前门萨国际的主席、人工智能专家和顾问)的文章,列举的大模型的数据集包括维基百科、书籍、期刊、Reddit链接、Common Crawl 和其他数据集等。
数据的多是一方面,另一方面,数据的丰富度、真实性也对大模型的训练至关重要。在训练的中后期,高质量数据将提升模型的精度。比如:
-
更加事实性的数据,将提升模型准确性;
-
更加通顺的中文语言,将提升模型理解中文语言能力;
-
更精准的垂类数据,能完成部分更细分领域的模型搭建。
另外,高质量反馈数据更能提高模型性能。比如,ChatGPT 采用人类强化学习 RLHF,通过更专业的问题、指令、人类反馈排序等加强模型理解人类语言逻辑。
对于国产大模型来说有两个挑战仍需努力:国内互联网语料质量相对较差,优质的中文标注数据集匮乏;标签主要通过人工标注,具体标注技术细节、对标注员的培训等仍需要国内科技企业探索。
大算力
数据提供的是房屋地基,能搭建的多高,取决于算力。算力是计算机系统的计算能力,也就是处理数据和执行计算任务的能力。
AI领域,由于深度神经网络需要进行大量的计算和训练,特别是对于大规模的模型和复杂的任务,需要更多的算力来支持。
以GPT大模型为例,随着 GPT、GPT-2 和 GPT-3(当前开放的版本为 GPT-3.5)的参数量从 1.17 亿增加到 1750 亿,预训练数据量从 5GB 增加到 45TB,算力需求随之增长。
因此,算力的提升可以提高模型的训练速度和效率,也可以提高模型的准确性和性能。
衡量头部厂商能否支撑训练及推理环节的算力需求,更多需要考虑两点:钱够不够,够多久,公司战略又是多久。
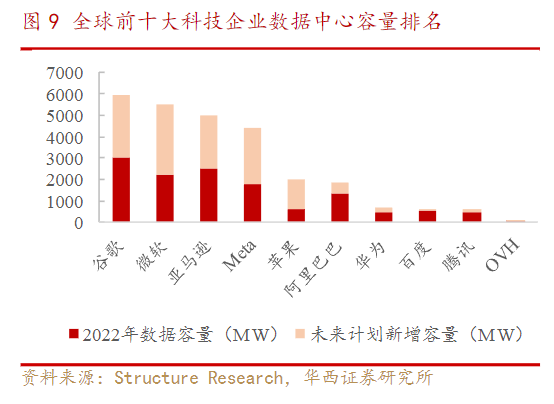
长线投入战略、充足资金预算,是复现 ChatGPT 所必须的要素。
以百度为例,2017 年提出“All IN AI”后,资本开支波动上升,去年全年资本开支(除爱奇艺)高达 181 亿元,同期经营现金流增长 30%至 261.7 亿元,截至 2022 年末公司用于进行资本支出的现金及现金等价物余额为 531.6 亿元,钱很够,也够很久。

另外,算力的基础设施其实是芯片,芯片性能越好,大模型的处理能力越快。这也是需要钱和战略支持规划的原因。
强算法
算法是一组解决问题的步骤和规则,可以用来执行特定的计算或操作。通常用于设计和实现计算机程序,以解决各种问题。
算法的好坏直接影响到程序的效率和性能。例如,ChatGPT 在算法上的突破更多在于思路而非具体理论,是“菜谱”而非“食材”的创新,这成为了复现的难点之一。
如何判断算法的好坏?主要有三点:空间复杂度、时间复杂度和鲁棒性。
-
时间就是算法完成任务所需的时间;
-
空间是指算法完成任务所需的内存空间;
-
鲁棒性是指算法对异常数据和噪声的容忍程度。
通常情况下,时间复杂度和空间复杂度越小,算法的效率越高。一个好的算法应该具有较高的鲁棒性,能够在各种情况下都能正确地执行任务,输出清晰的信息。
在实际应用中,可以根据具体需求和场景选择最适合的算法,综合考虑以上因素,找到一个平衡点。
例如,GPT就是在 Transformer 模型基础上发展的,Transformer 相比于传统的循环神经网络(RNN)或卷积神经网络(CNN),在处理长文本时,就具有更好的并行性和更短的训练时间,在成本、规模和效率之间实现了正确的权衡取舍。
从国产大模型角度看,算法、数据、算力壁垒并非不可逾越,随着人才流动、时间推移和研究进步,大模型性能很可能逐渐趋同。
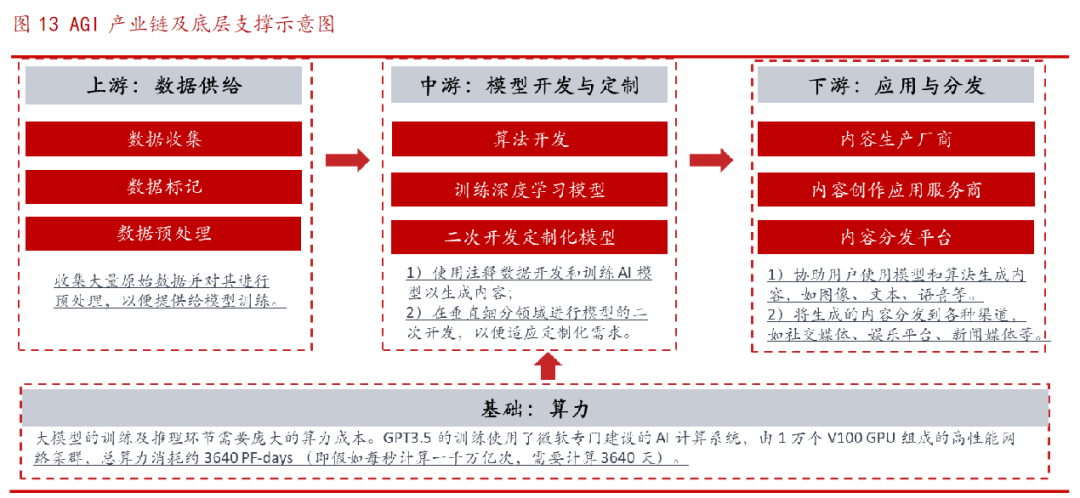
随着产业应用的深入、场景复杂度提升,随之而来的是数据的爆发式增长、算法的飞速更新迭代、算力的消耗指数上升,这些都对人工智能的发展提出新的要求。

普通人的机会
未来,传统的“掌握通识知识、流程性工作能力等”要求会逐步成为隐藏的底层要求,更显性、高层次的要求则是“创造性价值以及高效利用工具解决问题”的能力。
对于普通人来说,AI大模型带给我们的机会大致可以分为两类,一个是短期的投资机会,一个是长期的职业机会。
短期来看,在大模型领域有技术储备的公司更有优势,例如,腾讯控股、阿里巴巴、百度等。同时,可以关注已在视频、营销、阅读等相关细分领域抢跑的重点标的,例如科大讯飞、当虹科技、捷成股份、蓝色光标、风语筑、浙文互联等。
长期来看,借用陆奇在演讲时所说:“这个时代(大模型时代)跟淘金时代很像,如果你那个时候去加州淘金,一大堆人会死掉。但是卖勺子、卖铲子的人永远可以赚钱。”

人类技术驱动的创业创新,主要可以分为三种机会——底层技术,满足需求,改变世界。

第一种,最底层的数字化技术。数字化是人的延伸,包括GPT在内,目前发布的所有大模型AI,都是基于技术。包括英伟达、寒武纪这些芯片公司,也是为底层技术提供硬件设施。我们可以从中寻找合适自己的机会,或者为了这个职位努力完善自己的技能,例如前端、后端、设备、芯片等等。
第二种,是用技术去解决需求。需求可以分为两个方向:To C,可以用AI解决大家的娱乐、消费、社交、内容等,一切能够帮助人们过的更好的需求都需要被满足;To B,可以帮助企业降本增效。这部分的机会主要是与人接触,更好地了解用户需求,带来更好的产品或体验。
第三种是改变世界。比如能源科技,转化能源,或生命科学,或者是新的空间。例如马斯克正在做的机器人,脑机接口等等,甚至是元宇宙和Web 3。
陆奇在演讲中提到,他对大模型相关的看法:更大规模、更复杂的模型结构,意味着更广泛的应用领域,更多的机会——但一定要深思熟虑,先思考,再以行动导向。
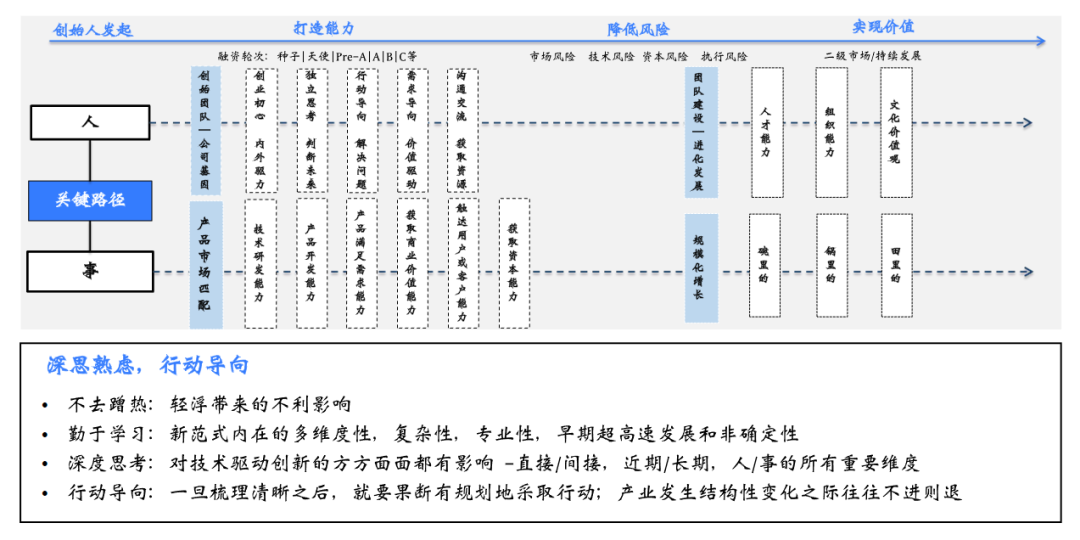
普通人的机会和大模型的发展非常相似,长期发展一定是技术驱动为主,但在落地的时候对需求的拆解、分析、梳理,把控好需求,是一切的一切。做到你能做到的,其他的,交给未来!
#大模型时代你觉得自己能做点啥?

发现报告商业局
发现报告旗下传递新经济商业知识的阵地。
我们需要先了解这个世界,才能思考,或创造。
